Reinforcement Learning (RL) Dota Bot
Dec 2018 - Mar 2019
Introduction
The bulk of the project consists out of two big components. The dotaservice that allows you to play Dota through and synchronous state-action loop using gRPC, and the dotaclient that has the code for the agents to play through the dotaservice, and a (distributed) optimizer that trains from experience, and creates new policies.
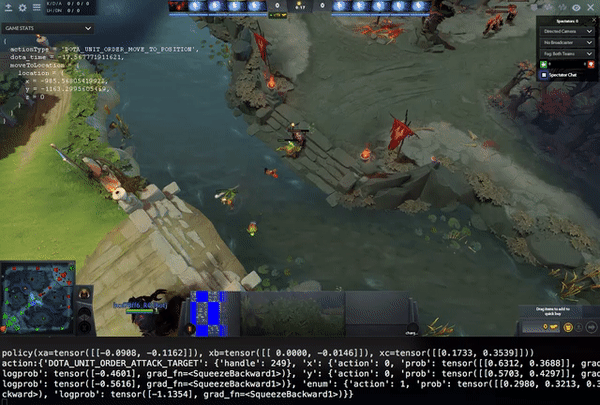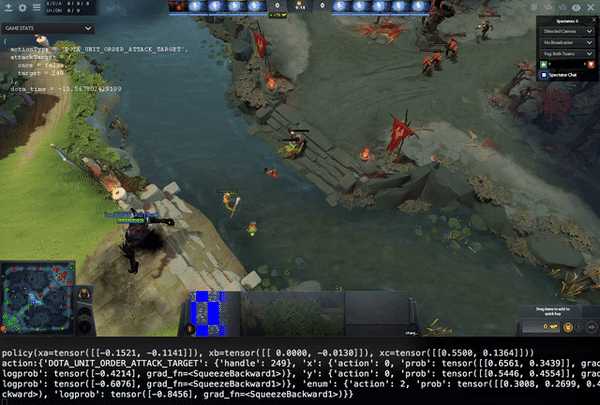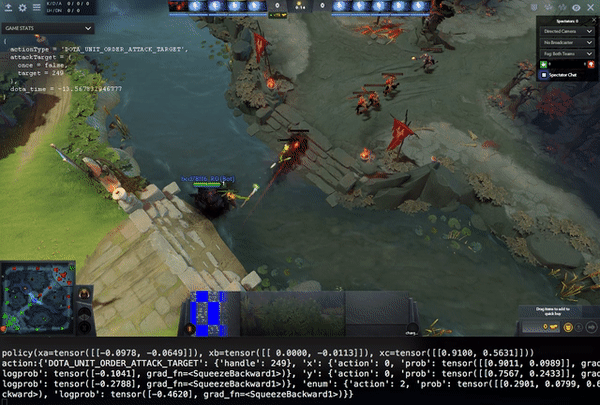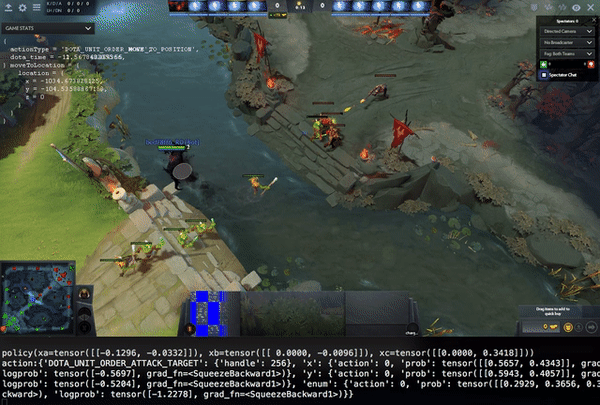
Above video shows a policy in a 1v1 self-play game. Manually reviewing like this is very important, because in self-play, you have very few metrics that give you an indication or baseline how good the policy is. For example: it’s easy to measure how many hot-dogs you can eat in a minute, but how do you express how good you are at e.g. Chess? And Dota is orders of magnitudes more complex than Chess.
Development
This project started with me trying to make a “proto2proto” model. This would take in a protobuf with some state observation, and output (maybe) another protobuf, with some action to be taken in that state. Using an RNN, I verified this worked great.
In a first iteration, I gave a string input like this: {"foo": 3, "zeus": 5} with a lot of
random keys and values. The task was for the model to return the number after zeus; so 5. This
turned out to be pretty easy and reliable.
The next task was to do some math. E.g. from an input like {"bla": 2, "foo": 3, "bar": 5}
it should add up all the values after the keys foo and bar, in this case 3+5=8. This also
turned out to be easy.
Then came Dota’s massive, repeated and nested 33kb protobuf. I had some ideas how to do this, but I figured I’d do an handcrafted version of this first. I never gotten around to trying my proto2proto idea.
System

Optimizer
The optimizer trains in A3C mode, it’s async, but not very off-policy. It every time the policy is updated, it is sent to the agents immediatelly, which then adopt it, even if they are mid-game. Advantage estimation is done through GAE, optimization using PPO.
Screenshots
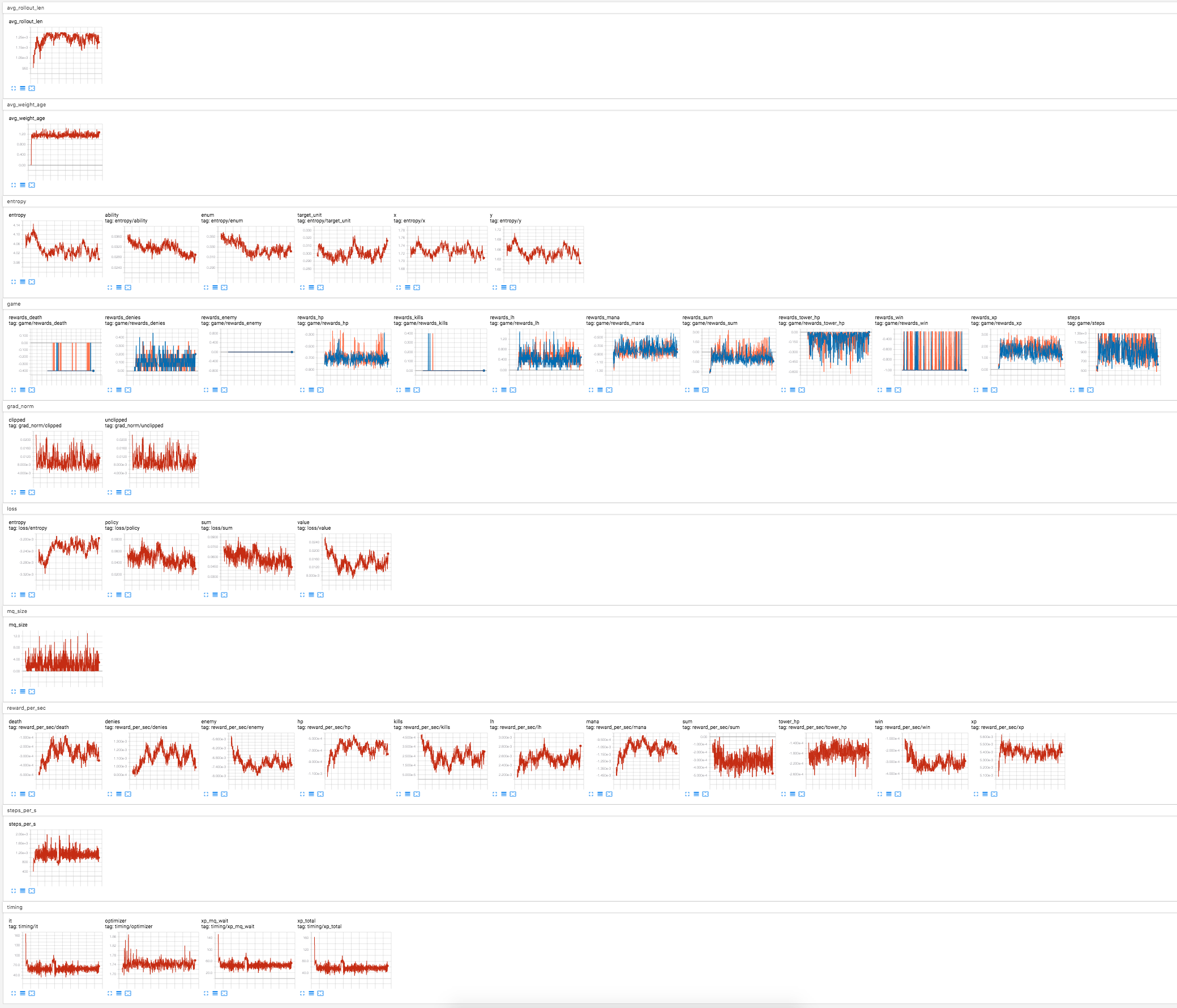 A view of tensorboard, hinting to the complexity of what’s going on. The trainer is in red, the
validation workers for dire and radiant are in orange and blue.
A view of tensorboard, hinting to the complexity of what’s going on. The trainer is in red, the
validation workers for dire and radiant are in orange and blue.
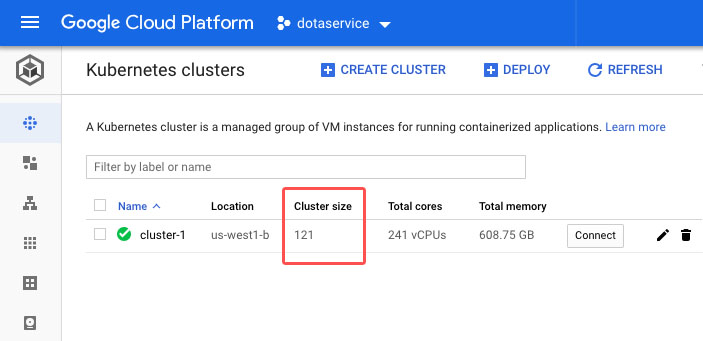 The dota cluster running on 120 nodes without breaking a sweat
The dota cluster running on 120 nodes without breaking a sweat
Resources
- experiment log (Google Doc)
- dotaservice
- dotaclient